Background
Recently, our team faced a challenge, how to detect the suspicious incorrect data from our vendor, in other words, our vendor sometimes will provides incorrect raw data to us. Unfortunately, we don’t have a solution to prevent this issue. As a result, we initially pass the incorrect data through the data pipeline across multiple services, leading to a series of data update errors. Most seriously, we end up providing entirely wrong information to our customers, which could increase product churn - something we definitely want to avoid.
Goal
First, let me introduce what the data looks like. It's a pure text data with the JSON format and includes multiple parts, and each file has slightly different to each other except one. If you’re interested, you can refer to the following link: GitHub Link, and you can also use the online JSON differ tools to help you recognized the difference quickly.
The file data/MAEU244638355-230015009-45b04974f7594ad299fca7fb5138ac36.json contains the anomaly because it has huge difference compare to others, and our goal is to come up with a solution that helps us identify it.
Solutions
How to find the way to identify the anomaly data? The first idea came to my mind is can I use the text similarity? why not use the hash function to do that? as the mention before where the files are all slightly different and only one file is significantly anomalous so a pure hash-based solution will not work effectively. After deciding the direction of solution, next I started to prepare the dataset and build the POC to verify it.
Compute Pairwise Similarity
- Normalize JSON files (sort keys, remove timestamps).
- Use a similarity metric to compare files.
- Cosine Similarity: Compare vectorized features of JSONs.
- Structural Similarity: Compare the structure and key counts.
Identify Anomaly
- Calculate the average similarity score for each file compared to the rest.
- The file with the lowest average similarity is the anomaly.
Based on these ideas, I’ve built the POC as outlined below. After running the program, as you can see, we successfully detected the incorrect data. You can review the code first; it’s not complicated, but there are some theoretical concepts I’ll explain in the next section.
import os
import json
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
import numpy as np
def normalize_json(json_data):
"""Normalize JSON for comparison by sorting keys."""
return json.dumps(json_data, sort_keys=True)
def compute_similarity(json_files):
"""Compute similarity scores between JSON files."""
normalized_files = []
for file_path in json_files:
with open(file_path, 'r') as f:
data = json.load(f)
normalized_files.append(normalize_json(data))
# Vectorize the normalized JSON files
vectorizer = TfidfVectorizer()
tfidf_matrix = vectorizer.fit_transform(normalized_files)
# Compute pairwise cosine similarity
similarity_matrix = cosine_similarity(tfidf_matrix)
return similarity_matrix
def detect_anomaly(json_files):
"""Detect the anomalous file based on similarity scores."""
similarity_matrix = compute_similarity(json_files)
avg_similarity = similarity_matrix.mean(axis=1)
# Find the file with the lowest average similarity
anomaly_index = np.argmin(avg_similarity)
anomaly_file = json_files[anomaly_index]
return anomaly_file, avg_similarity
# Load all JSON files from the "data" folder
data_folder = "data" # Replace with your folder name
json_files = [os.path.join(data_folder, file) for file in os.listdir(data_folder) if file.endswith('.json')]
print(json_files)
# Detect the anomaly
if json_files:
anomaly_file, avg_similarity = detect_anomaly(json_files)
print(f"Anomalous file detected: {anomaly_file}")
print("Average Similarity Scores:", avg_similarity)
else:
print("No JSON files found in the specified folder.")
➜ python anomaly_detection.py
['data/MAEU244638355-230015009-45b04974f7594ad299fca7fb5138ac36.json', 'data/MAEU244638355-229834907-111a125fff524e568539fa9ee1259cc9.json', 'data/MAEU244638355-226316743-999b976a3e3147cdbefcb89497bcc8b0.json', 'data/MAEU244638355-228799200-1d919c554e0643c7869dcafe06206f12.json', 'data/MAEU244638355-227412648-4ab0fcecc65441b1800033f0ddcddd67.json']
Anomalous file detected: data/MAEU244638355-230015009-45b04974f7594ad299fca7fb5138ac36.json
Average Similarity Scores: [0.91224814 0.96954086 0.96806412 0.97184808 0.96856012]Implementation Details
Now, let's dive deeper into the code. The POC consists of serveral key steps, each with its specific purpose:
- Normalization: JSON files are normalized by sorting keys to ensure a consistent stucture.
- TF-IDF Vectorization: Converts the normalized JOSN strings into a vectorized form.
- Cosine Similarity: Measures the pairwise similarity between the files.
- Anomaly Detection: Identifies the file with lowest average similarity score.
Next I will explain the TF-IDF and Cosine Similarity, both of them are simple and easy concept for text analysis.
TF-IDF
The TF-IDF stands for Term Frequency-Inverse Document Frequency, a common technique in natural language processing (NLP) to represent text data in a way that reflects the importance of word in a collection of documents.
Term Frequency (TF)
- Measure how often a term (word) appears in a document
- Formular:
$$ TF(t) = {\text{Number of times term t appears in a document} \over \text{Total number of terms in the document}} $$
Inverse Document Frequency (IDF)
- Measure how important a term is. Terms that occur in many documents are less significant.
- Formular:
$$ IDF(t) = {log{\text{Total number of documents} \over \text{Number of documents containing t}}} $$
TF-IDF Weight
- Combine TF and IDF to assign a weight to each term in each document.
- Formular:
$$ \text{TF-IDF(t)} = {\text{TF(t)} \over \text{IDF(t)}} $$
What the tfidf_matrix Contains
The tfidf_matrix is a 2D sparse matrix where:
- Rows represent the documents (in this case, normalized JSON files).
- Columns represent unique terms (words) across all documents.
- Each entry (i, j) in the matrix is the TF-IDF weight of the term
jin documenti.
Why use the TF-IDF
- Handles Variability in JSON Files: Converts textual differences (e.g., slight variations in keys or values) into comparable numerical data.
- Ignores Common Words: Words that appear in all files (e.g., "is", "a") get lower weights, focusing comparisons on more distinctive terms.
- Captures Structure: By flattening and normalizing JSON into strings, TF-IDF indirectly captures the structure and content differences between files.
Cosine Similarity
When translating data from text to vectors, there are many mathematical formulas and concepts that can guide us. Here, we choose cosine similarity, which is commonly used to calculate the similarity between two vectors. You can refer to the figure below to visualize this.
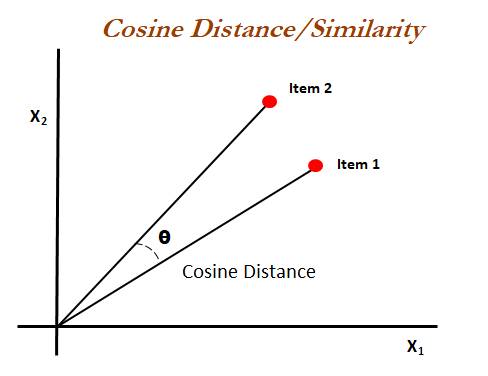
The cosine similarity formular comes from the definitin of dot product, in the 2D space the definition of dot product is
$$ {{\mathbf{A} \cdot \mathbf{B}} = {|\mathbf{A}| |\mathbf{B}|}}{\cos(\theta)} $$
then we can get the cosine similarity is
$$ \text{Cosine Similarity} = \cos(\theta) = \frac{\mathbf{A} \cdot \mathbf{B}}{|\mathbf{A}| |\mathbf{B}|} $$
Takeaways
In this blog, I demonstrated how to use TF-IDF and Cosine Similarity with JSON normalization to build a simple anomaly detection system for a text dataset. We also explained what TF-IDF and Cosine Similarity are, and I hope these concepts will be useful to you in the future.

