Background
As AI & ML technologies mature, more and more companies are beginning to explore the integration of these technologies into their internal products. Bringing AI & ML solutions to companies poses a significant challenge in recent years.
This post will introduce how to use Airflow to build a small MLOps project aimed at providing a machine learning (ML) pipeline to reduce the cost of deploying ML models. Additionally, we will take some time to discuss modularization in Airflow.
For this demonstration, we have selected the Titanic competition, a renowned challenge on Kaggle, as our example dataset. For detailed installation instructions and settings, please refer to my Github repo.
ML Pipeline Lifecycle
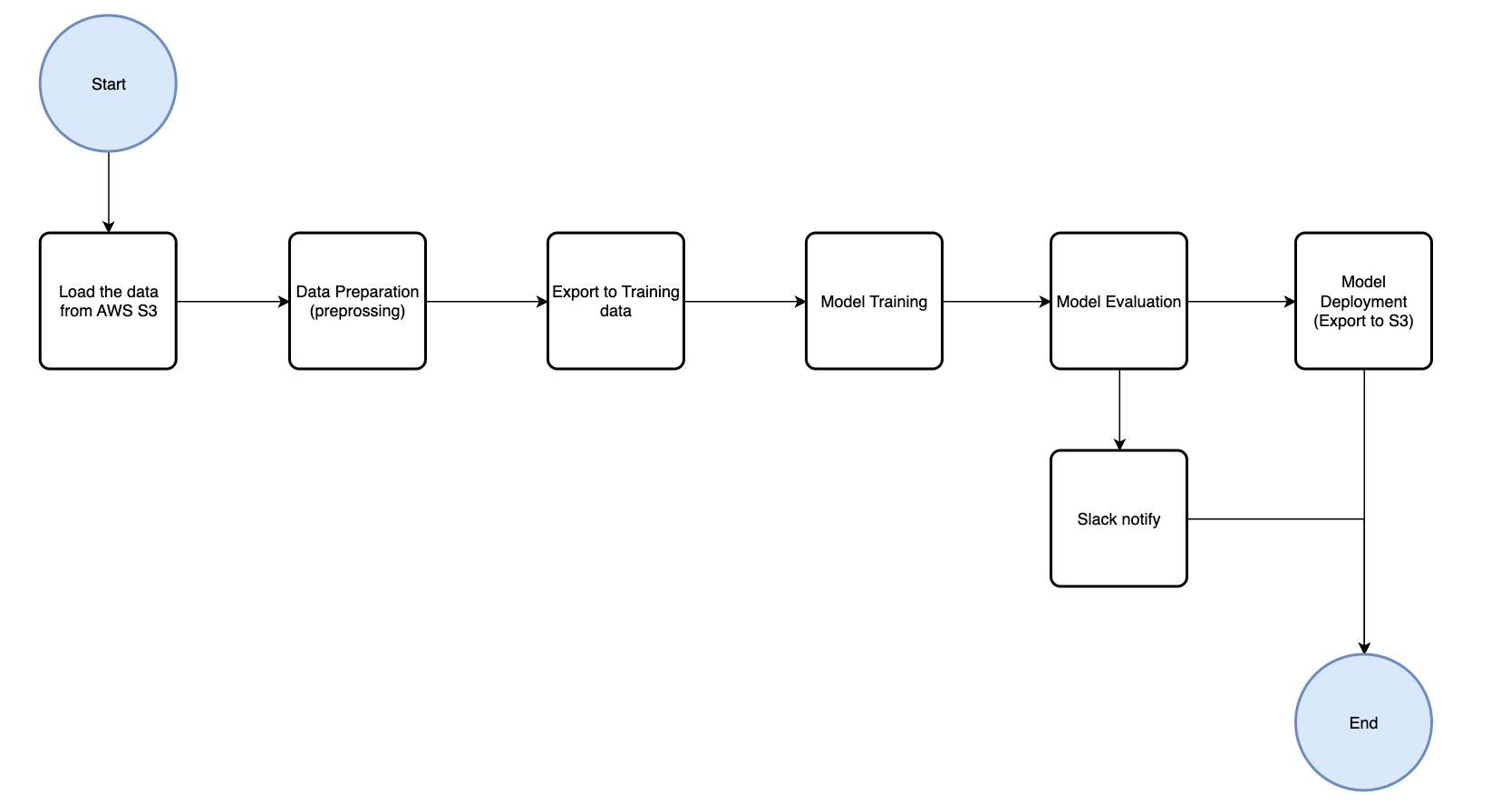
As you can see, I have defined the basic pipeline as shown in the figure above. However, due to differences in business models and architectures among different companies, you may need to make some adjustments to fit your current architecture.
I referred to several articles and videos to define the basic pipeline flow for beginners:
- Step 1: We will load the raw data from S3, and here we will use LocalStack to help us implement this function in our local environment.
- Step 2: Prepare the training data for the model, including data preprocessing, feature selection, etc.
- Step 3: Export the training data for model training.
- Step 4: Perform model training.
- Step 5: Export the evaluation results to users via notification solutions such as Slack or Telegram messages.
- Step 6: Export the model to S3.
Then I divided these steps within the pipeline to the four groups:
- Data Preparation Group
- Model Training Group
- Model Deployment Group
- Notification Group
All implementations revolve around this pipeline flow and these four groups, and these definitions serve as the fundamental concepts of modularization."
Modularization
Next, let's delve into modularization within the Airflow project. Most articles and online resources tend to place all related code in a single file. However, from my perspective, this approach becomes challenging to maintain as the project grows. Therefore, I have explored how to modularize within Airflow myself and developed a final solution.
For each task (i.e., the problem you want to solve using ML), we will create a main DAG file and related functions, which will be organized into different files to achieve modularization.
- dags: This directory contains the main DAG (Directed Acyclic Graph) functions.
- dags/func: Within this directory, sub-folders are organized for modularization. Each folder name corresponds to a main DAG function. Inside each sub-folder, the entire ML pipeline is divided into different steps, with each step having its own file to complete the related function.
The tree structure looks like:
./dags
├── __init__.py
├── func
│ ├── __init__.py
│ └── titanic
│ ├── __init__.py
│ ├── data_preparation.py
│ ├── model_deployment.py
│ ├── model_training.py
│ └── notification.py
└── titanic.pyWe have a main DAG file named titanic and a sub-folder under func also named titanic. This structure signifies that all functions within this folder are related to the main DAG titanic. This approach allows us to easily organize the folder architecture for multiple ML tasks.
titanic.py
from datetime import datetime, timedelta
import json
import pickle
import base64
import pandas as pd
from airflow.decorators import task
from airflow.decorators import dag
from airflow.utils.dates import days_ago
from airflow.providers.amazon.aws.transfers.local_to_s3 import LocalFilesystemToS3Operator
from airflow.utils.task_group import TaskGroup
from func.titanic.data_preparation import load_data_from_s3, data_preprocessing, export_the_training_data_to_s3, delete_temp_file
from func.titanic.model_training import get_dataset, train_model, evaluate_model
from func.titanic.model_deployment import save_model
@dag(schedule_interval='@daily', start_date=days_ago(1), catchup=False, tags=['example'])
def titanic_flow():
with TaskGroup("data_preparation_group") as data_preparation:
data = load_data_from_s3()
train_data = data_preprocessing(data) # type: ignore
tmp_filename = export_the_training_data_to_s3(train_data) # type: ignore
upload_to_s3_task = LocalFilesystemToS3Operator(
task_id='upload_to_s3',
filename=tmp_filename,
dest_key='titanic/train.csv',
dest_bucket='airflow',
aws_conn_id='aws_localstack', # Airflow AWS connection ID which can be created through the UI
replace=True,
)
tmp_filename >> upload_to_s3_task
upload_to_s3_task >> delete_temp_file(tmp_filename)
with TaskGroup("model_training") as model_training:
dataset = get_dataset(data=train_data)
model = train_model(dataset['X'], dataset['y'])
results = evaluate_model(model, dataset['X'], dataset['y'])
with TaskGroup("model_deployment") as model_deployment:
# Save the trained model to a temporary file
model_file_path = save_model(model)
# Task to upload the model to S3
upload_model_to_s3 = LocalFilesystemToS3Operator(
task_id='upload_model_to_s3',
filename=model_file_path,
dest_key='titanic/titanic_model.pkl',
dest_bucket='airflow',
aws_conn_id='aws_localstack',
replace=True,
)
results >> model_file_path >> upload_model_to_s3
dag = titanic_flow()As you can see, the main DAG function's result is now very simple and clear. We have successfully abstracted away the details into other functions, allowing the main DAG function to focus solely on the data flow and data passing. Not bad, right?
Some Tips
Passing data between each step was the most challenging part during the implementation of this demo project. Perhaps because I was not very familiar with Airflow at the time, I often encountered XComArg-related error messages like the following. This occurred because Airflow automatically wraps your return value in an XComArg. If you want to return multiple values in a single function, please remember to return them in dictionary format instead of tuple format.
Argument of type "XComArg" cannot be assigned to parameter "data" of type "DataFrame"
"XComArg" is incompatible with "DataFrame"PylancereportGeneralTypeIssues
(variable) train_data: XComArgKey Takeaways
In this post, I have demonstrated how to build a simple MLOps pipeline using Python and Airflow. We also discussed modularization in Airflow, although it may not be the optimal solution (as I am still exploring better approaches), I believe I have shared some valuable insights that may prompt you to rethink your approach.
Next, there are several areas where this demo project can be further improved, including:
- DAG and unit testing
- Container development environment setup
- Multi-model comparison flow
- Deployment with tags
- Notification implementation
- Integration of CI/CD into the MLOps workflow
- Debugging production code
In conclusion, I hope you found my ideas on modularizing your Airflow project helpful, and I look forward to continuing to explore the world of Airflow and MLOps in the future. Cheers!

